大奖章基金,深度学习方法能用来炒股吗?
潜江龙资讯网
金融市场,作为深度学习应用的重要场景之一,一直以来都有使用深度学习来炒股的论文、研究成果的发布大奖章基金。但很多都是尝试性的方法。机器之心就曾报道过很多用深度学习来炒股的教程。
 下面,我们介绍下早稻田大学的一位同学使用多个监督学习和强化学习模型在金融市场的应用,作者主要描述了多个论文的核心思想与实现,并且全面概括了其在 Github 上维护的项目。
下面,我们介绍下早稻田大学的一位同学使用多个监督学习和强化学习模型在金融市场的应用,作者主要描述了多个论文的核心思想与实现,并且全面概括了其在 Github 上维护的项目。
 项目地址:://github.com/Ceruleanacg/Personae
项目地址:://github.com/Ceruleanacg/Personae
 目前,在本项目中:
目前,在本项目中:
 实现了 4 个强化学习模型。
实现了 4 个强化学习模型。
 实现了 3 个监督学习模型。
实现了 3 个监督学习模型。
 实现了 1 个简单的交易所,提供基本的买入、持有、卖出操作(卖空仍在开发中),标的物可以是股票组合或者期货合约组合。
实现了 1 个简单的交易所,提供基本的买入、持有、卖出操作(卖空仍在开发中),标的物可以是股票组合或者期货合约组合。
 对于监督学习模型的数据集:
对于监督学习模型的数据集:
 我们采用 2008 年 1 月 1 日到 2018 年 1 月 1 日这个区间内,
我们采用 2008 年 1 月 1 日到 2018 年 1 月 1 日这个区间内,
 招商银行(600036)
招商银行(600036)
 交通银行(601328)
交通银行(601328)
 中信银行(601998)
中信银行(601998)
 工商银行(601389)
这四只银行股在第 T 天的,
开盘价(Open)
收盘价(Close)
最高价(High)
最低价(Low)
交易量(Volume)
作为输入数据,第 T+1 天的收盘价(Close)作为输出数据,进行训练,其中,这个区间前 70% 的数据作为训练数据,后 30% 作为测试数据,目前没有设置验证集数据。
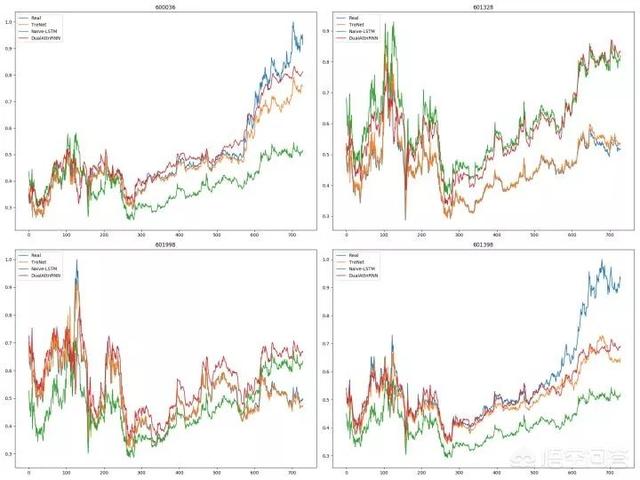
下图是目前的实验结果,就目前的实验结果来看,监督学习的表现要好于强化学习。
图例 :蓝色的折线是测试数据集,其他颜色的折线是三种不同的监督学习模型在测试集上的预测。
接下来,我们将会依次对这 3 个监督学习模型与 4 个强化学习模型做一个简短的介绍。
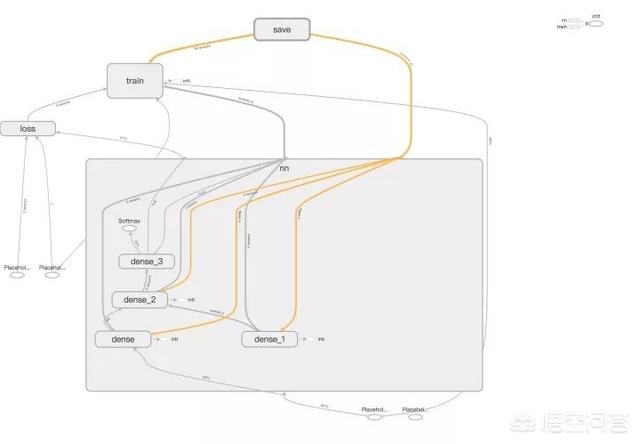
1. Naive-LSTM (LSTM)
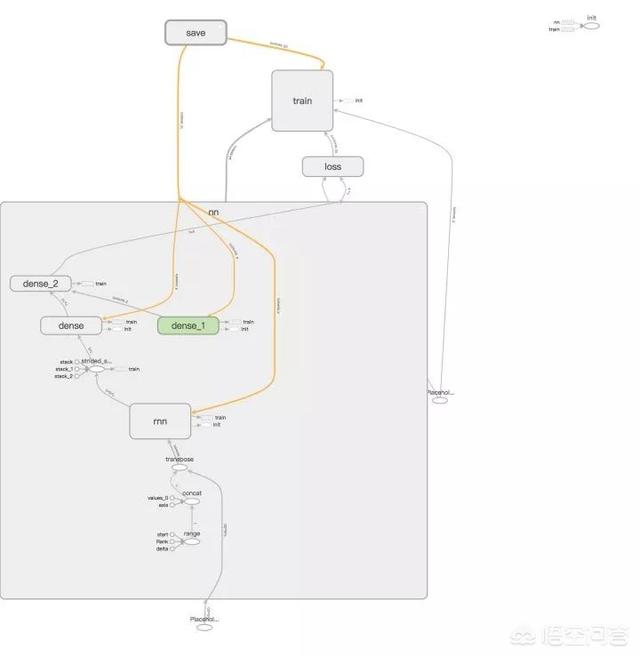
该模型是基于 LSTM 和 Dense(全连接)的基本模型,输入是序列长度为 5,即第 T 到第 T+4 天的 OCHLV 数据,输出是一个实数,代表了第 T+5 的预测收盘价格。
arXiv:1506.02078: Visualizing and Understanding Recurrent Network
模型计算图:
2. TreNet (HNN)
IJCAI 2017. Hybrid Neural Networks for Learning the Trend in Time Series
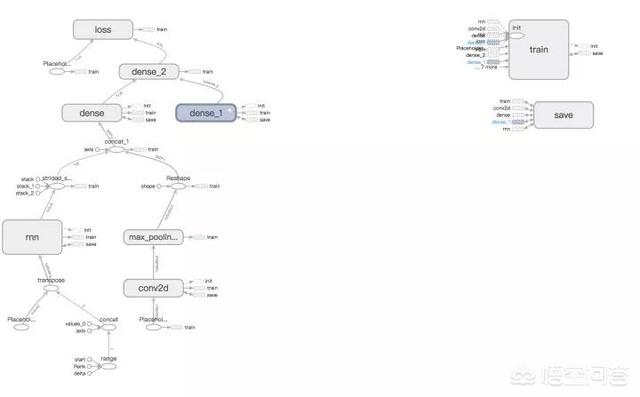
上述引用的论文提出了一种混合神经网络的结构,同时用 RNN 与 CNN 提取序列特征,然后将输出拼接作为全连接层的输入,最后输出最终的预测结果。
模型计算图:
3. DA-RNN (DualAttnRNN)
arXiv:1704.02971: A Dual-Stage Attention-Based Recurrent Neural Network for Time Series Prediction
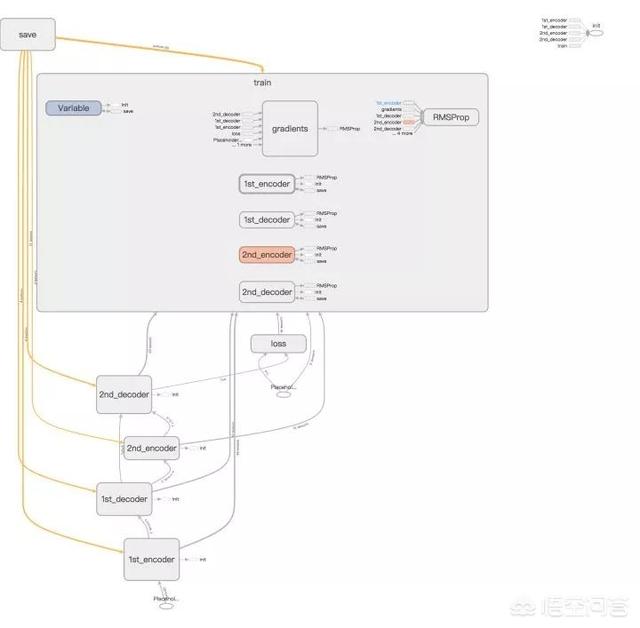
上述引用的论文提出了一种基于注意力机制(Attention Based Model)的与 Seq-to-Seq 模型的网络结构,其创新点在于该模型连续两次使用注意力机制,在对原始序列使用注意力机制求权重后再次使用注意力机制对编码后的序列求权重,然后经解码与全连接层后输出结果。
模型计算图:
以上是关于项目中监督学习模型的简短介绍,其中,所有模型的具体实现可以在项目链接中看到。
接下来是关于 3 个强化学习模型的介绍,但是在介绍强化学习模型前,我们首先对强化学习的数据和环境一个简短的概述。
Financial Market
这个文件实现了三个核心类,分别是:
Market
Trader
Position
他们分别代表了市场、交易员、持仓信息,最终 Market 类作为 Agent(强化学习模型)的 Environment(环境),接受 Agent 的 Action(动作),同时给出 Next State(下一状态)和 Reward(奖励),并进行迭代。
对于强化学习使用的数据,
我们使用这四只银行股在第 T 天的,
开盘价(Open)
收盘价(Close)
最高价(High)
最低价(Low)
交易量(Volume)
和交易员在第 T 天的,
现金(Cash)
持仓价值(Holding Value)
各持仓量(Holding Amount)
作为 State(状态),使用交易指令,
买入(Buy)
卖出(Sell)
持有(Hold)
接下来是关于实验结果与强化学习模型的介绍:
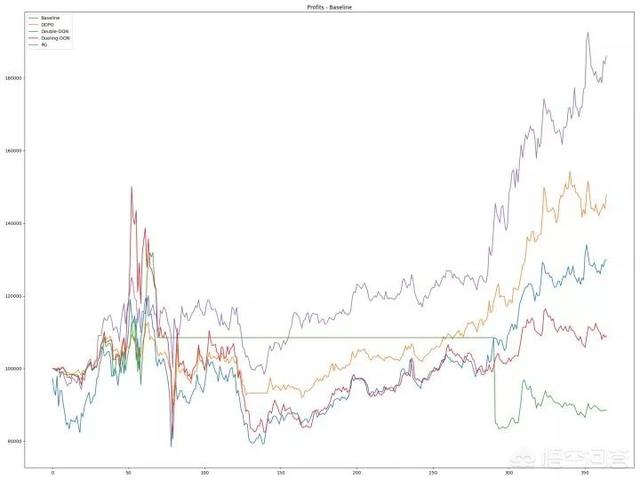
图例 - 横坐标是时间,纵坐标是利润,其中蓝色折线是基准线,其他颜色的折线是强化学习模型表现
可以看出,除了 Policy Gradient 可以跑赢基准收益外,其他强化学习模型的收益甚至不如基准,这里非常值得讨论,目前笔者也在尝试从参数、输入特征、输出特征、奖励函数等多个角度考虑解决该问题。
接下来是关于强化学习模型的介绍:
1. Policy Gradient
NIPS. Vol. 99. 1999: Policy gradient methods for reinforcement learning with function approximation
模型计算图:
Basic Policy Gradient 的思想很朴素,重复及可能多的采样,对于一次采样的所有动作中,根据奖励函数值的正负决定梯度下降的方向,从而提高或者降低这些动作出现的概率。
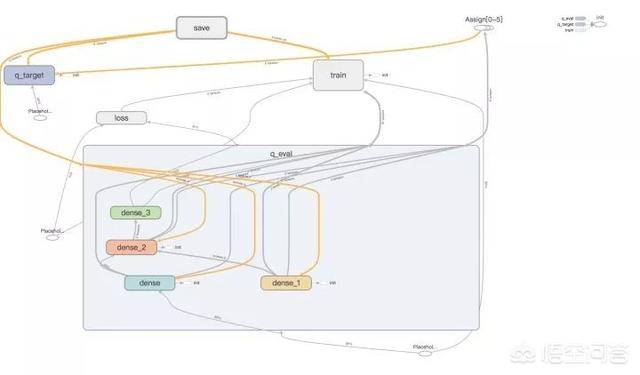
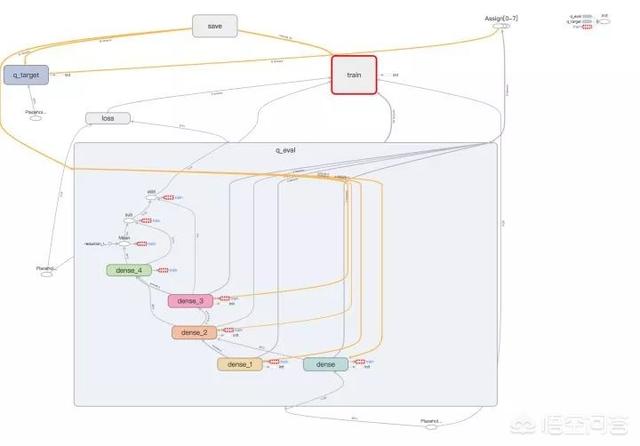
2. Double DQN
arXiv:1509.06461: Deep Reinforcement Learning with Double Q-learning
模型计算图:
Double-DQN 采用评估网络与目标网络相互制约,期望避免传统 DQN 中容易出现的过度估计问题。首先使用评估网络预测下一个状态的状态-动作函数值,然后选取取得最大值的动作,计做 a_{max},接着用目标网络预测下一状态与采用 a_{max} 的状态值计算标签,然后期望最小化标签与评估网络对当前状态的状态-动作函数和当前动作的 Q 的均方差。
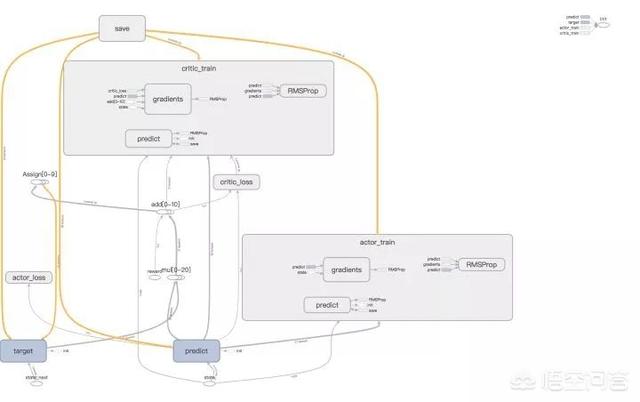
3. Deep Deterministic Policy Gradient (DDPG)
arXiv:1509.02971: Continuous control with deep reinforcement learning
模型计算图:
DDPG 用于连续动作空间,在本问题中,对于四只股票的买卖持有的动作被映射到区间 [0, 11],其中,DDPG 使用 Actor-Critic Model,引入评估 Actor,目标 Actor 模型与评估 Critic,目标 Critic 模型两组四个网络,其中 Actor 模型用于预测动作,Critic 模型用于评估当前状态与动作的分数(状态-动作值函数),该方法期望最小化:评估 Critic 与评估 Actor 对当前状态-动作函数值与目标 Critic 和目标 Actor 对下一状态-动作函数值的均方差(如算法图所示),依次迭代改进目标 Critic 和目标 Actor。
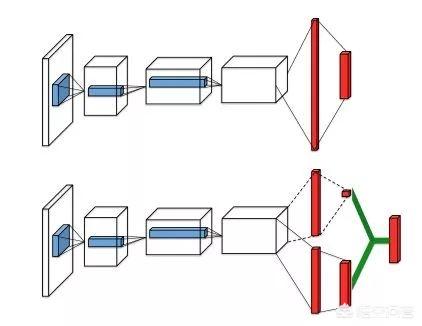
4. Dueling-DQN
arXiv:1511.06581: Dueling Network Architectures for Deep Reinforcement Learning
模型计算图:
算法:
相对于 DQN 直接输出状态-动作函数值,Dueling-DQN 的状态-动作函数值由上式决定,从网络结构上可以看出,在输出状态-动作函数值前,Dueling-DQN 的结构拆分了原 DQN 网络结构的最后一层,这样的思想很像 Actor-Critic 模型中的 Baseline,因为并不是每个状态都是十分重要的,有些时候对于这些状态,采取那个动作都不会有很大的影响。
即最终对于某个状态-动作函数值而言,Advantage 的在不同动作维度上的值一定意义上描述了这个动作对于这个状态的重要性,最后加上 Q 值,避免了过度估计。
以上是最近关于强化学习和监督学习在金融市场中的一些应用和相关论文方法的实现。
目前仍有以下问题亟待探讨与解决:
强化学习模型奖励函数的设计
强化学习中基于值迭代的算法难以收敛
监督学习的特征维度如何扩展
同时,项目中可能有 Bug,欢迎各种 Issue 提出以及欢迎贡献各种代码 : )
工商银行(601389)
这四只银行股在第 T 天的,
开盘价(Open)
收盘价(Close)
最高价(High)
最低价(Low)
交易量(Volume)
作为输入数据,第 T+1 天的收盘价(Close)作为输出数据,进行训练,其中,这个区间前 70% 的数据作为训练数据,后 30% 作为测试数据,目前没有设置验证集数据。
下图是目前的实验结果,就目前的实验结果来看,监督学习的表现要好于强化学习。
图例 :蓝色的折线是测试数据集,其他颜色的折线是三种不同的监督学习模型在测试集上的预测。
接下来,我们将会依次对这 3 个监督学习模型与 4 个强化学习模型做一个简短的介绍。
1. Naive-LSTM (LSTM)
该模型是基于 LSTM 和 Dense(全连接)的基本模型,输入是序列长度为 5,即第 T 到第 T+4 天的 OCHLV 数据,输出是一个实数,代表了第 T+5 的预测收盘价格。
arXiv:1506.02078: Visualizing and Understanding Recurrent Network
模型计算图:
2. TreNet (HNN)
IJCAI 2017. Hybrid Neural Networks for Learning the Trend in Time Series
上述引用的论文提出了一种混合神经网络的结构,同时用 RNN 与 CNN 提取序列特征,然后将输出拼接作为全连接层的输入,最后输出最终的预测结果。
模型计算图:
3. DA-RNN (DualAttnRNN)
arXiv:1704.02971: A Dual-Stage Attention-Based Recurrent Neural Network for Time Series Prediction
上述引用的论文提出了一种基于注意力机制(Attention Based Model)的与 Seq-to-Seq 模型的网络结构,其创新点在于该模型连续两次使用注意力机制,在对原始序列使用注意力机制求权重后再次使用注意力机制对编码后的序列求权重,然后经解码与全连接层后输出结果。
模型计算图:
以上是关于项目中监督学习模型的简短介绍,其中,所有模型的具体实现可以在项目链接中看到。
接下来是关于 3 个强化学习模型的介绍,但是在介绍强化学习模型前,我们首先对强化学习的数据和环境一个简短的概述。
Financial Market
这个文件实现了三个核心类,分别是:
Market
Trader
Position
他们分别代表了市场、交易员、持仓信息,最终 Market 类作为 Agent(强化学习模型)的 Environment(环境),接受 Agent 的 Action(动作),同时给出 Next State(下一状态)和 Reward(奖励),并进行迭代。
对于强化学习使用的数据,
我们使用这四只银行股在第 T 天的,
开盘价(Open)
收盘价(Close)
最高价(High)
最低价(Low)
交易量(Volume)
和交易员在第 T 天的,
现金(Cash)
持仓价值(Holding Value)
各持仓量(Holding Amount)
作为 State(状态),使用交易指令,
买入(Buy)
卖出(Sell)
持有(Hold)
接下来是关于实验结果与强化学习模型的介绍:
图例 - 横坐标是时间,纵坐标是利润,其中蓝色折线是基准线,其他颜色的折线是强化学习模型表现
可以看出,除了 Policy Gradient 可以跑赢基准收益外,其他强化学习模型的收益甚至不如基准,这里非常值得讨论,目前笔者也在尝试从参数、输入特征、输出特征、奖励函数等多个角度考虑解决该问题。
接下来是关于强化学习模型的介绍:
1. Policy Gradient
NIPS. Vol. 99. 1999: Policy gradient methods for reinforcement learning with function approximation
模型计算图:
Basic Policy Gradient 的思想很朴素,重复及可能多的采样,对于一次采样的所有动作中,根据奖励函数值的正负决定梯度下降的方向,从而提高或者降低这些动作出现的概率。
2. Double DQN
arXiv:1509.06461: Deep Reinforcement Learning with Double Q-learning
模型计算图:
Double-DQN 采用评估网络与目标网络相互制约,期望避免传统 DQN 中容易出现的过度估计问题。首先使用评估网络预测下一个状态的状态-动作函数值,然后选取取得最大值的动作,计做 a_{max},接着用目标网络预测下一状态与采用 a_{max} 的状态值计算标签,然后期望最小化标签与评估网络对当前状态的状态-动作函数和当前动作的 Q 的均方差。
3. Deep Deterministic Policy Gradient (DDPG)
arXiv:1509.02971: Continuous control with deep reinforcement learning
模型计算图:
DDPG 用于连续动作空间,在本问题中,对于四只股票的买卖持有的动作被映射到区间 [0, 11],其中,DDPG 使用 Actor-Critic Model,引入评估 Actor,目标 Actor 模型与评估 Critic,目标 Critic 模型两组四个网络,其中 Actor 模型用于预测动作,Critic 模型用于评估当前状态与动作的分数(状态-动作值函数),该方法期望最小化:评估 Critic 与评估 Actor 对当前状态-动作函数值与目标 Critic 和目标 Actor 对下一状态-动作函数值的均方差(如算法图所示),依次迭代改进目标 Critic 和目标 Actor。
4. Dueling-DQN
arXiv:1511.06581: Dueling Network Architectures for Deep Reinforcement Learning
模型计算图:
算法:
相对于 DQN 直接输出状态-动作函数值,Dueling-DQN 的状态-动作函数值由上式决定,从网络结构上可以看出,在输出状态-动作函数值前,Dueling-DQN 的结构拆分了原 DQN 网络结构的最后一层,这样的思想很像 Actor-Critic 模型中的 Baseline,因为并不是每个状态都是十分重要的,有些时候对于这些状态,采取那个动作都不会有很大的影响。
即最终对于某个状态-动作函数值而言,Advantage 的在不同动作维度上的值一定意义上描述了这个动作对于这个状态的重要性,最后加上 Q 值,避免了过度估计。
以上是最近关于强化学习和监督学习在金融市场中的一些应用和相关论文方法的实现。
目前仍有以下问题亟待探讨与解决:
强化学习模型奖励函数的设计
强化学习中基于值迭代的算法难以收敛
监督学习的特征维度如何扩展
同时,项目中可能有 Bug,欢迎各种 Issue 提出以及欢迎贡献各种代码 : )


