手机黑客需要学什么软件下载,想学黑客技术,哪些论坛和书籍适合入门
潜江龙资讯网
emmm手机黑客需要学什么软件下载,要学的东西还是挺多的。我总结了一下自己在学习过程中的经验和东西,希望可以帮助到题主。
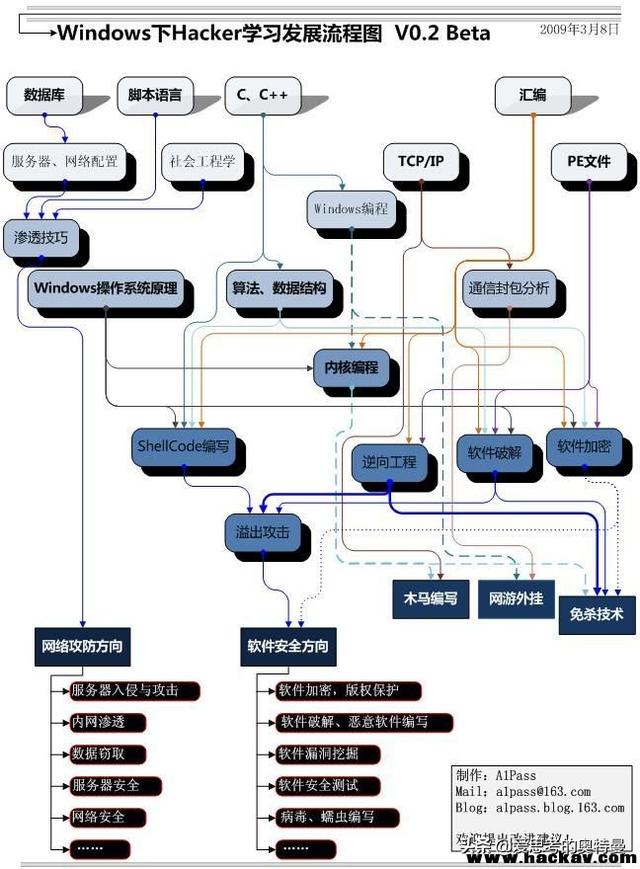 有句话必须说在前面:不要拿技术来搞破坏!不要拿技术来做违法的事情!一切都是出于学习的目的!
有句话必须说在前面:不要拿技术来搞破坏!不要拿技术来做违法的事情!一切都是出于学习的目的!
 黑客入门知识:C语言和TCP/IP 想当黑客没问题,先好好学习C语言,不敢说精通,毕竟很多C语言做了十几年的人也不敢说自己精通C语言,但一定要达到很熟练的地步。C语言的教程网上有很多,所以这里不在推荐。
黑客入门知识:C语言和TCP/IP 想当黑客没问题,先好好学习C语言,不敢说精通,毕竟很多C语言做了十几年的人也不敢说自己精通C语言,但一定要达到很熟练的地步。C语言的教程网上有很多,所以这里不在推荐。
 为什么要学习C?因为C语言也是几乎所有底层系统的语言!正是因为如此,深刻的学会C语言,并理解其运行原理对底层攻击有着重要的意义。简单的如学会scanf、sprintf之类的带来的溢出攻击的原理。深入一点的要学会堆栈传参数的原理,以及常见系统调用的位置,这对一个黑客来讲是至关重要的。
就算一个黑客厉害的能上天,脱离了网络他也什么都干不了,所以掌握网络相关的知识也是必须要求,比如TCP/IP协议。推荐书籍:TCP/IP详解(四卷)
黑客进阶学:社会工程学,渗透,逆向算法用一年的时间打好C语言和网络知识的相关基础后,就可以进行到下一步了。
先说社会工程学,这是一门很有意思的学科。世界第一黑客凯文·米特尼克在《反欺骗的艺术》中曾提到,人为因素才是安全的软肋。很多企业、公司在信息安全上投入大量的资金,最终导致数据泄露的原因,往往却是发生在人本身。你们可能永远都想象不到,对于黑客们来说,通过一个用户名、一串数字、一串英文代码,社会工程师就可以通过这么几条的线索,通过社工攻击手段,加以筛选、整理,就能把你的所有个人情况信息、家庭状况、兴趣爱好、婚姻状况、你在网上留下的一切痕迹等个人信息全部掌握得一清二楚。虽然这个可能是最不起眼,而且还是最麻烦的方法。一种无需依托任何黑客软件,更注重研究人性弱点的黑客手法正在兴起,这就是社会工程学黑客技术;
接着就是渗透,其实就是对于服务器的一种攻击手法,一种通过模拟使用黑客的技术和方法,挖掘目标系统的安全漏洞,取得系统的控制权,访问系统的机密数据,并发现可能影响业务持续运作安全隐患的一种安全测试和评估方式。常见的有黑盒,白盒和灰盒测试。
逆向算法俗称“解密”,想学解密就必须先懂得加密,一些常用的加密算法,比如RSA,DES,三重DES加密,各类对称加密和非对称加密等等。总之学好线性代数和离散数学是很有必要的,这个我学的也不好,所以就不多说了……
推荐论坛:I春秋,里面大佬很多。
基本上就讲这么多吧,单是上述内容就已经够我们学个五六年了,如果加上汇编,操作系统原理,数据库等等还要花更多的时间。当然了我推荐第一步先开始学英语和高等数学,一步步慢慢来,功夫到了自然就会水到渠成啦!
(都看到最后了,麻烦点个赞和关注吧,谢谢)
这里有2种方法,一个是利用现有的爬虫软件,一个是利用编程语言,下面我简单介绍一下,主要内容如下:
为什么要学习C?因为C语言也是几乎所有底层系统的语言!正是因为如此,深刻的学会C语言,并理解其运行原理对底层攻击有着重要的意义。简单的如学会scanf、sprintf之类的带来的溢出攻击的原理。深入一点的要学会堆栈传参数的原理,以及常见系统调用的位置,这对一个黑客来讲是至关重要的。
就算一个黑客厉害的能上天,脱离了网络他也什么都干不了,所以掌握网络相关的知识也是必须要求,比如TCP/IP协议。推荐书籍:TCP/IP详解(四卷)
黑客进阶学:社会工程学,渗透,逆向算法用一年的时间打好C语言和网络知识的相关基础后,就可以进行到下一步了。
先说社会工程学,这是一门很有意思的学科。世界第一黑客凯文·米特尼克在《反欺骗的艺术》中曾提到,人为因素才是安全的软肋。很多企业、公司在信息安全上投入大量的资金,最终导致数据泄露的原因,往往却是发生在人本身。你们可能永远都想象不到,对于黑客们来说,通过一个用户名、一串数字、一串英文代码,社会工程师就可以通过这么几条的线索,通过社工攻击手段,加以筛选、整理,就能把你的所有个人情况信息、家庭状况、兴趣爱好、婚姻状况、你在网上留下的一切痕迹等个人信息全部掌握得一清二楚。虽然这个可能是最不起眼,而且还是最麻烦的方法。一种无需依托任何黑客软件,更注重研究人性弱点的黑客手法正在兴起,这就是社会工程学黑客技术;
接着就是渗透,其实就是对于服务器的一种攻击手法,一种通过模拟使用黑客的技术和方法,挖掘目标系统的安全漏洞,取得系统的控制权,访问系统的机密数据,并发现可能影响业务持续运作安全隐患的一种安全测试和评估方式。常见的有黑盒,白盒和灰盒测试。
逆向算法俗称“解密”,想学解密就必须先懂得加密,一些常用的加密算法,比如RSA,DES,三重DES加密,各类对称加密和非对称加密等等。总之学好线性代数和离散数学是很有必要的,这个我学的也不好,所以就不多说了……
推荐论坛:I春秋,里面大佬很多。
基本上就讲这么多吧,单是上述内容就已经够我们学个五六年了,如果加上汇编,操作系统原理,数据库等等还要花更多的时间。当然了我推荐第一步先开始学英语和高等数学,一步步慢慢来,功夫到了自然就会水到渠成啦!
(都看到最后了,麻烦点个赞和关注吧,谢谢)
这里有2种方法,一个是利用现有的爬虫软件,一个是利用编程语言,下面我简单介绍一下,主要内容如下:
 爬虫软件这个就很多了,对于稍微简单的一些规整静态网页来说,使用Excel就可以进行爬取,相对复杂的一些网页,可以使用八爪鱼、火车头等专业爬虫软件来爬取,下面我以八爪鱼为例,简单介绍一下爬取网页过程,很简单:
爬虫软件这个就很多了,对于稍微简单的一些规整静态网页来说,使用Excel就可以进行爬取,相对复杂的一些网页,可以使用八爪鱼、火车头等专业爬虫软件来爬取,下面我以八爪鱼为例,简单介绍一下爬取网页过程,很简单:
 1.首先,下载八爪鱼软件,这个直接到官网上下载就行,如下,直接点击下载:
1.首先,下载八爪鱼软件,这个直接到官网上下载就行,如下,直接点击下载:
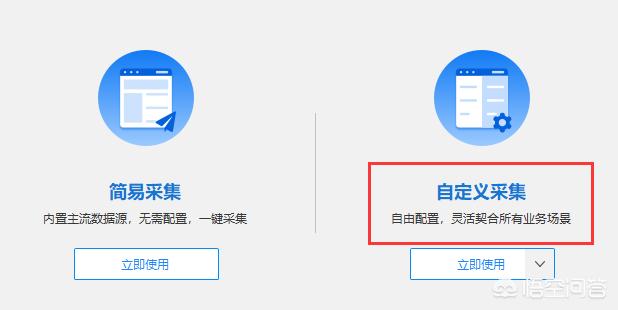
 2.下载完成后,打开软件,进入任务主页,这里选择“自定义采集”,点击“立即使用”,如下:
2.下载完成后,打开软件,进入任务主页,这里选择“自定义采集”,点击“立即使用”,如下:
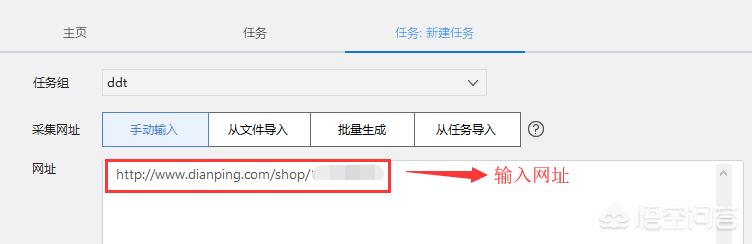
 3.进入新建任务页面,然后输入需要爬取的网页地址,点击保存,如下,这里以大众点评上的评论数据为例:
3.进入新建任务页面,然后输入需要爬取的网页地址,点击保存,如下,这里以大众点评上的评论数据为例:

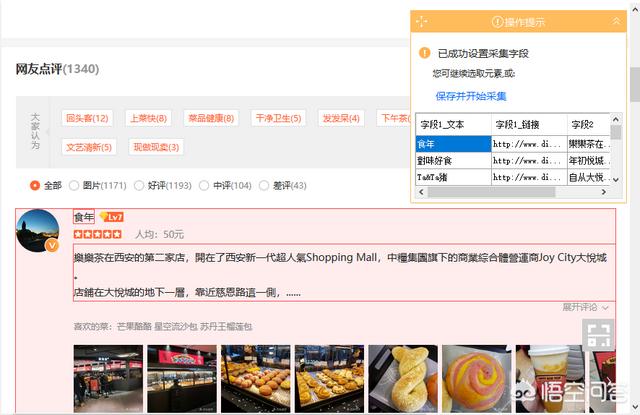
 4.点击“保存网址”后,就会自动打开页面,如下,这时你就可以根据自己需求直接选择需要爬取的网页内容,然后按照提示一步一步往下走就行:
4.点击“保存网址”后,就会自动打开页面,如下,这时你就可以根据自己需求直接选择需要爬取的网页内容,然后按照提示一步一步往下走就行:
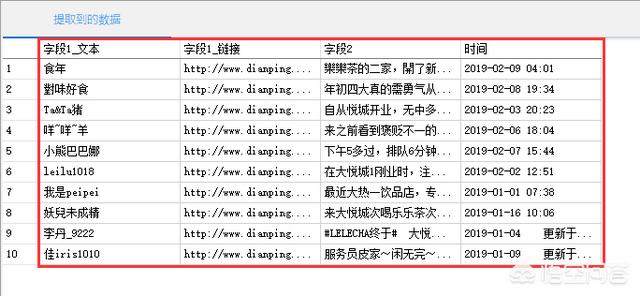
 5.最后启动本地采集,就会自动爬取刚才你选中的数据,如下,很快也很简单:
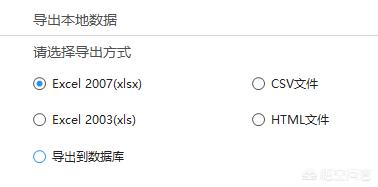
这里你可以导出为Excel文件,也可以导出到数据库中都行,如下:
编程语言这个也很多,大部分编程语言都可以,像Java,Python等都可以实现网页数据的爬取,如果你没有任何编程基础的话,可以学习一下Python,面向大众,简单易懂,至于爬虫库的话,也很多,像lxml,urllib,requests,bs4等,入门都很简单,这里以糗事百科的数据为例,结合Python爬虫实现一下:
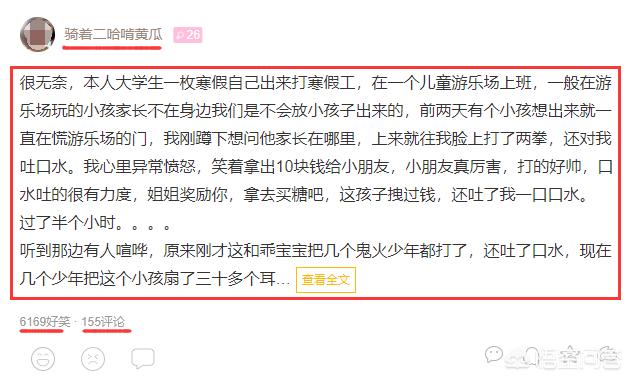
1.首先,打开任意一个页面,爬取的网页数据如下,主要包括昵称、内容、好笑数和评论数4个字段:
2.接着打开网页源码,可以看到,爬取的内容都在网页源码中,数据不是动态加载的,相对爬取起来就容易很多,如下:
3.最后就是根据网页结构,编写相关代码了,这里主要使用的是requests+BeautifulSoup组合,比较简单,其中requests用于请求页面,BeautifulSoup用于解析页面,主要代码如下:
点击运行程序,就会爬取到刚才的网页数据,如下:
4.这里熟悉后,为了提高开发的效率,避免重复造轮子,可以学习一下相关爬虫框架,如Python的Scrapy等,很不错,也比较受欢迎:
至此,我们就完成了网页数据的爬取。总的来说,两种方法都可以,如果你不想编程,或者没有任何的编程基础,可以考虑使用八爪鱼等专业爬虫软件,如果你有一定的编程基础,想挑战一下自己,可以使用相关编程语言来实现网页数据的爬取,网上也有相关教程和资料,感兴趣的话,可以搜一下,希望以上分享的内容能对你有所帮助吧,也欢迎大家评论、留言。
5.最后启动本地采集,就会自动爬取刚才你选中的数据,如下,很快也很简单:
这里你可以导出为Excel文件,也可以导出到数据库中都行,如下:
编程语言这个也很多,大部分编程语言都可以,像Java,Python等都可以实现网页数据的爬取,如果你没有任何编程基础的话,可以学习一下Python,面向大众,简单易懂,至于爬虫库的话,也很多,像lxml,urllib,requests,bs4等,入门都很简单,这里以糗事百科的数据为例,结合Python爬虫实现一下:
1.首先,打开任意一个页面,爬取的网页数据如下,主要包括昵称、内容、好笑数和评论数4个字段:
2.接着打开网页源码,可以看到,爬取的内容都在网页源码中,数据不是动态加载的,相对爬取起来就容易很多,如下:
3.最后就是根据网页结构,编写相关代码了,这里主要使用的是requests+BeautifulSoup组合,比较简单,其中requests用于请求页面,BeautifulSoup用于解析页面,主要代码如下:
点击运行程序,就会爬取到刚才的网页数据,如下:
4.这里熟悉后,为了提高开发的效率,避免重复造轮子,可以学习一下相关爬虫框架,如Python的Scrapy等,很不错,也比较受欢迎:
至此,我们就完成了网页数据的爬取。总的来说,两种方法都可以,如果你不想编程,或者没有任何的编程基础,可以考虑使用八爪鱼等专业爬虫软件,如果你有一定的编程基础,想挑战一下自己,可以使用相关编程语言来实现网页数据的爬取,网上也有相关教程和资料,感兴趣的话,可以搜一下,希望以上分享的内容能对你有所帮助吧,也欢迎大家评论、留言。
